In Q1 of 2026, AI startups raised $255.5 billion globally. That’s not a typo. A quarter trillion dollars. In three months. And here’s the thing — that single quarter blew past the entire 2025 full-year total for AI venture funding.
I’ve been tracking startup funding for years and I’ve never seen anything like it. Not during the dot-com era. Not during the mobile app gold rush. Not during the crypto boom. The scale of capital moving into AI right now is genuinely unprecedented, and if you’re not paying close attention to where it’s going — and more importantly, where it isn’t — you’re missing the actual story.
So let’s talk about it. Not the press release version. The uncomfortable one.
Three Companies, Two-Thirds of Everything
PitchBook dropped a report a few days ago that should honestly be required reading for anyone in this industry. Of that $255.5 billion in Q1, three companies — OpenAI, Anthropic, and xAI — accounted for $172 billion. That’s 67.3% of all AI venture capital.
Let that sit for a second.
The remaining $83.5 billion got split across 1,543 other companies. Quick math: that’s about $54 million per company on average. But averages lie, and they lie hard here. The median AI VC deal size in 2025 was $5 million. The mean was $35.8 million. The gap between those two numbers tells you everything about how concentrated this market has become. A tiny handful of deals at the top are yanking the averages up while most AI startups are raising perfectly normal, unremarkable rounds.
And it’s getting worse, not better. Foundational AI companies — the ones building the actual models — raised $178 billion in Q1 2026 across just 24 deals. Twenty-four. In all of 2025, that category did $88.9 billion across 66 deals. The number of companies getting funded at this level is shrinking while the check sizes are exploding.
There’s a word for this dynamic and it’s not “healthy ecosystem.”
Here it is, in case you want to stare at the numbers directly:
Segment
Companies
Funding (Q1 2026)
Share
The Big Three — OpenAI, Anthropic, xAI
3
$172 billion
67.3%
Everyone else
1,543
$83.5 billion
32.7%
Total
1,546
$255.5 billion
100%
Three companies. Two-thirds of the money. The “everyone else” bucket works out to roughly $54 million per company on average — but remember, the median deal was $5 million. Most of those 1,543 companies raised far less than the average suggests.
Follow the Money (It’s Not VC Anymore)
One of the weirder subplots that doesn’t get enough attention: venture capital isn’t really driving this anymore.
Corporate venture capital now represents 43% of AI startup funding. Sovereign wealth funds are piling in. Microsoft, Amazon, Google, NVIDIA — they’re not writing checks because they want 10x returns on a Series B. They’re writing checks because they need to lock down compute agreements, secure cloud revenue, and make sure they don’t get left behind in a platform shift that could eat their existing businesses.
When Microsoft disclosed that 45% of its $625 billion cloud backlog was tied to OpenAI, the stock dropped 12% in a single day. That’s $440 billion in market cap. Evaporated. Because investors suddenly realized that a huge chunk of Microsoft’s future revenue depends on a company that burns $17 billion a year and doesn’t expect to turn a profit until 2030.
That’s not a venture capital relationship. That’s a dependency. And it’s not limited to Microsoft.
The “investment” flowing into these companies is increasingly circular. Microsoft invests in OpenAI, which spends the money on Azure compute, which shows up as Microsoft cloud revenue, which justifies the investment. Amazon invests in Anthropic, Anthropic buys AWS compute, Amazon reports cloud growth. Around and around it goes. Everyone’s revenue is someone else’s cost. It works brilliantly until someone decides the music stopped.
The Unit Economics Are Brutal
Let’s look at OpenAI, since they’re the biggest and most transparently messy.
They’re targeting about $30 billion in revenue for 2026. That sounds impressive — and it is, in absolute terms. But they’re burning roughly $17 billion to get there. Their own internal projections show losses tripling to $14 billion this year against roughly $13 billion in sales, with total spending around $22 billion. They lost $13.5 billion in just the first half of 2025.
Every dollar of revenue costs them more than a dollar to generate. The cumulative burn from 2025 through 2029? An estimated $115 billion.
Let me put OpenAI’s numbers in one place, because seeing them side by side makes the absurdity harder to ignore:
Metric
2025
2026 (Projected)
Revenue
Not disclosed
~$30B
Net Loss
$13.5B (H1 only)
~$14B
Cash Burn
—
~$17B
Total Spending
—
~$22B
Valuation
$300B (Mar round)
~$850B (Mar round)
Forward Revenue Multiple
—
~28x
They’re valued at roughly $850 billion as of their March 2026 round. At $30 billion in projected revenue, that’s somewhere around 28x forward revenue. For a company with negative gross margins. In what universe is that sustainable?
Anthropic is doing better on the surface — they surprised everyone by hitting a $30 billion annualized run-rate earlier this year. But they’re also burning cash at a pace that makes traditional SaaS investors queasy, and their valuation sits around $380 billion. The model providers are in an arms race where the cost of competing goes up faster than the revenue does. Every new model generation requires more compute, more data, more infrastructure, and the pricing pressure from open-source alternatives and Chinese competitors means you can’t just pass those costs to customers.
A quick side-by-side puts the two Western leaders in perspective:
Metric
OpenAI
Anthropic
Valuation
~$850B
~$380B
2026 Revenue (projected)
~$30B
$30B annualized run-rate
2026 Cash Burn
~$17B
Not disclosed
Path to Profitability
2029 target
Not disclosed
Key Strategic Backer
Microsoft
Amazon
Revenue Multiple
~28x forward
~12.7x (on run-rate)
Anthropic’s multiple looks almost reasonable by comparison. Almost. Neither company has demonstrated that selling intelligence at scale produces software-like margins rather than infrastructure-like ones.
And then there’s DeepSeek. In February 2026, they launched V4 — a trillion-parameter coding model with a million-token context window. Built at a fraction of the cost of Western frontier models. If Chinese labs can produce competitive AI without burning through $17 billion a year, the entire “scale is the moat” thesis falls apart. You don’t need a fancy financial model to see the problem there.
What About Everyone Else?
The non-foundational-model startups — the application layer, the vertical SaaS plays, the tooling companies — are living in a completely different reality from the handful of giants at the top.
They’re raising at perfectly normal multiples. The AI startup valuation range in 2026 is wide — 10x to 50x revenue, with the median landing somewhere around 20x to 30x. But those multiples come with strings attached. Investors are asking harder questions than they were two years ago. What’s your moat, really? What happens when the model providers ship a feature that does 80% of what your product does? How defensible is your data advantage?
The application-layer AI companies that are actually doing well tend to have one thing in common: they’re not just thin wrappers around someone else’s API. They own a workflow. They have proprietary data. They solve a problem that’s too specific, too regulated, or too operationally complex for a horizontal model provider to bother with. Everything else is walking dead — it just doesn’t know it yet.
And early-stage funding? It’s getting squeezed. Only 14% of AI mega-deals in 2025 were early-stage. The money is flowing to the companies that already raised billions, not to the ones trying to raise their first million. That’s a problem for the ecosystem long-term, even if nobody wants to talk about it while the party’s still going.
Is This a Bubble?
I get asked this constantly. And the honest answer is: it depends on what you mean by “bubble.”
If you mean “are AI company valuations completely unhinged from economic reality?” — yes, absolutely. The S&P 500 is trading at 23x forward earnings, the most stretched it’s been since the dot-com era. The Bank of England formally warned about overvaluation risks in the AI sector. A National Bureau of Economic Research study found that 90% of firms report no measurable productivity impact from AI yet — but executives project it will increase productivity by 1.4%. That gap between expectation and reality is exactly the kind of thing that precedes a correction.
US mega-caps are expected to spend $1.1 trillion on AI between 2026 and 2029. Total AI spending is expected to surpass $1.6 trillion. Those are staggering numbers, and they assume a level of return that nobody has demonstrated yet.
But here’s the counterargument, and it’s not nothing: the dot-com comparison misses something important. In 2000, most of the money went into companies with no revenue, no infrastructure, and no real technology moat. Pets.com sold dog food online. Today’s AI giants are building actual infrastructure — data centers, custom silicon, model architectures that take years to develop. You can correct the valuation of a software company overnight. You can’t wish a $15 billion data center out of existence. The physical assets create a floor that the dot-com era never had.
What we’re probably heading for isn’t a pop. It’s a slow, grinding correction. The absurd valuations will come down. The “we put a chatbot on it” companies will disappear. The conversation will get more boring and more useful. That’s actually healthy.
The risk isn’t that AI fails. The risk is that the returns don’t justify the $1.6 trillion price tag. And that’s a much more interesting problem to think about.
What This Means If You’re Building
I’ll keep this practical because that’s what actually matters.
If you’re raising at the application layer, you need to be able to answer one question cold: what happens when OpenAI or Anthropic ships your feature? If your answer is “they won’t” or “our data moat is too deep,” you’d better have receipts. The model providers are not sitting still. They’re vacuuming up talent, acquiring companies, and expanding into enterprise workflows. Complacency is a death sentence.
If you’re an early-stage founder, the funding environment is probably tighter than the headline numbers suggest. Yes, $255 billion moved in Q1. Almost none of it went to pre-seed or seed-stage AI companies. You’re competing for attention in a market where the mega-rounds suck up all the oxygen. That means you need to be capital-efficient by default, not by aspiration. The burn multiple — how much you spend for every dollar of new recurring revenue — has become the investor metric of choice in 2026. AI-native startups that use automation to keep burn multiples below 1.0x are getting funded. Everyone else is fighting uphill.
And here’s something nobody in Silicon Valley wants to admit out loud: 29% of startups fail because they run out of money. Not because the product was bad. Not because the market wasn’t there. They just ran out of cash. In an environment where capital is concentrating at the top, that number goes up. If you’re building, know your runway down to the week. Twelve to eighteen months is comfortable. Anything under six is emergency mode.
The brutal truth about AI funding in 2026: there’s more money in the system than ever before, and it’s never been harder to get your hands on it unless you’re already one of the chosen few. The concentration at the top masks how competitive things are for everyone else. And the unit economics at the top suggest that even the chosen few haven’t figured out how to make the math work.
That’s not a reason to be bearish on AI. The technology is real, the adoption is real, and the long-term trajectory is up and to the right. But the funding environment has gotten weird in ways that reward skepticism. The people who win in markets like this are the ones who can tell the difference between a genuine growth story and a money-go-round — and who have the discipline to build something that works even when the easy money dries up.
Something strange happened between late 2025 and early 2026. The conversation around AI agents stopped being about “what if” and became about “how.” In boardrooms, developer channels, and startup pitch decks, the question shifted almost overnight: not whether agents will transform software, but which architecture, which framework, and what guardrails will get them into production without blowing up.
The numbers tell part of the story. The global AI agents market hit roughly $10.9 billion in 2026, up from $7.6 billion the year before — a 43% single-year jump that makes the early cloud migration look leisurely by comparison. Grand View Research projects the market reaching $50.3 billion by 2030 at a 45.8% CAGR, and some analysts extend that line all the way to $236 billion by 2034. AI startups raised $202 billion in 2025 alone, a 75% increase year-over-year, with 55 startups closing rounds of $100 million or more. Gartner expects that by the end of 2026, 40% of enterprise applications will embed task-specific AI agents.
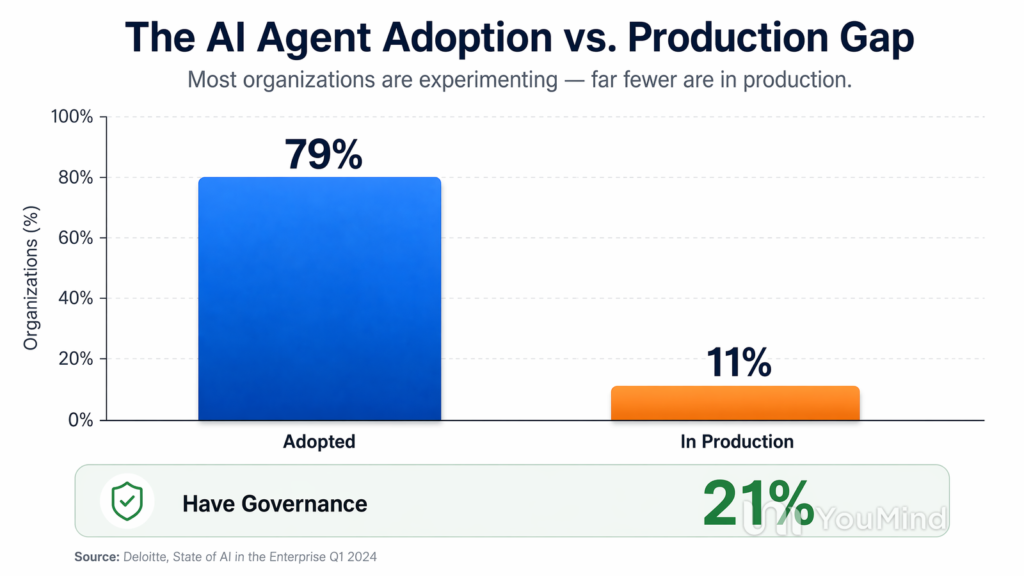
But numbers only get you so far. Beneath the market enthusiasm sits a more interesting — and more honest — reality: enterprises are adopting AI agents at an astonishing 79% rate, yet only 11% have them running in production. That gap is not a footnote. It is the defining tension of the agentic moment.
The Gap Is the Story
Almost four in five enterprises have experimented with or deployed AI agents in some form. But only one in nine is running them in production. Only 21% of companies have a mature governance model for agents, according to Deloitte’s State of AI 2026 report. And here is the stat that should keep founders up at night: 88% of organizations deploying agents report security incidents, and one in eight security breaches now involve agentic systems. Only 23% of enterprises have agent-specific security frameworks in place.
What does this tell us? The technology has raced ahead of the operating model. Building an agent that works in a demo is straightforward — every major framework can get you there in an afternoon. Building one that runs reliably in production, handles edge cases gracefully, and doesn’t create new attack surfaces is an entirely different discipline. Most teams are still in the demo phase because the gap between “it works” and “it’s safe to deploy” is larger than anyone anticipated.
This is, oddly, good news for startups and builders who are paying attention. The gap is where value gets created. If everyone were already in production, the opportunity would be commoditized. The fact that 68% of enterprises are still figuring out the bridge from pilot to production means there is enormous room for tools, platforms, and practices that close it.
What an AI Agent Actually Is in 2026
If you have been following the space, you have probably noticed that the word “agent” has been stretched to the breaking point. Every chatbot wrapper, every RAG pipeline, every prompt template now calls itself an agent. That ambiguity is not just sloppy marketing — it creates real confusion about what to build and how to evaluate it.
In 2026, a meaningful definition has crystallized: an AI agent is a system that does not just respond to prompts but can reason, plan, and execute multi-step goals autonomously within a defined environment. The key words are plan, execute, and autonomously. A single-turn chatbot is not an agent. A system that calls an API once and formats the response is not an agent. An agent decides what to do next, which tool to use, and whether its own output is good enough — and then loops until the task is done.
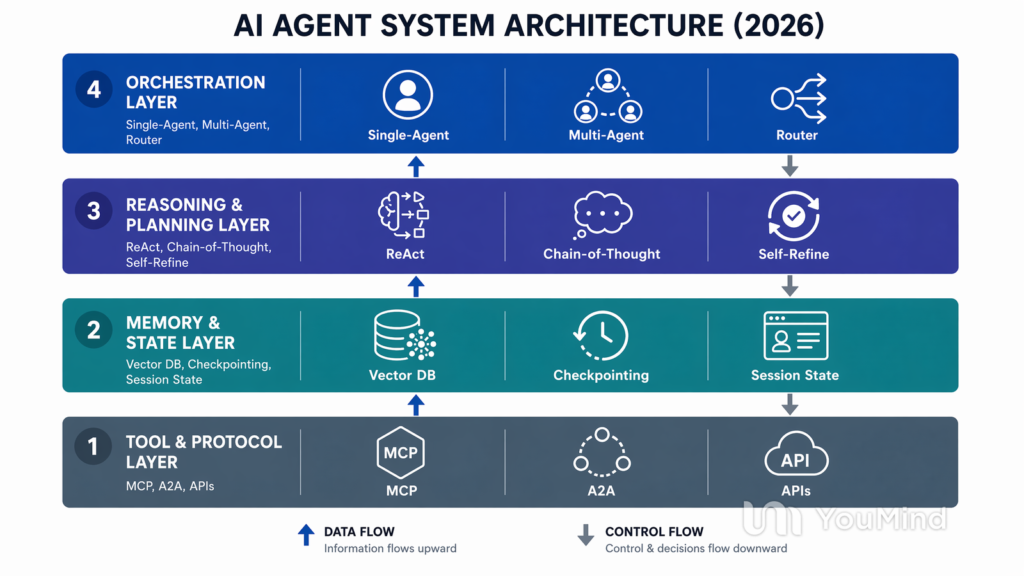
Under the hood, modern agent systems are composed of four distinct architectural layers.
The Tool and Protocol Layer sits at the base. This is where agents connect to the outside world — APIs, databases, file systems, and increasingly, standardized protocols like the Model Context Protocol (MCP) and Agent-to-Agent Protocol (A2A). MCP, in particular, has become the closest thing the industry has to a universal connector, removing the need for bespoke integrations for every tool an agent might call. The shift is significant: in 2024, connecting an agent to a new data source meant writing custom glue code. In 2026, you register a tool once through a standard protocol and every compliant agent can discover and use it.
The Memory and State Layer handles what the agent remembers across turns, sessions, and tasks. This is where things get hard. Vector databases store semantic recall, checkpointing systems (LangGraph’s built-in time-travel debugging is the gold standard here) persist agent state, and session management ensures continuity. The unsolved problem: long-horizon memory. Agents still lose context over dozens of steps, and the compounding error problem — where small mistakes in step three cascade into catastrophic failures by step thirty — remains one of the biggest barriers to production deployment.
The Reasoning and Planning Layer is where the model decides what to do. The dominant patterns in 2026 are ReAct (Reason + Act, interleaving thought and tool calls), Chain-of-Thought with self-consistency, and increasingly sophisticated self-refinement loops where the agent evaluates its own output and iterates. Reinforcement Learning with Verifiable Rewards (RLVR), popularized by DeepSeek-R1 and now adopted across the industry, has made reasoning models dramatically better at staying on track over multi-step tasks. But even the best models still drift, hallucinate, and get trapped in unproductive loops.
The Orchestration Layer is the top of the stack — and the most architecturally consequential decision a team will make. This is where you choose between a single-agent system (one model driving the entire workflow), a multi-agent system (specialized agents collaborating on subtasks), or a router pattern (a lightweight model deciding which specialized agent to invoke). Most production systems in 2026 start single-agent and only expand to multi-agent when the task complexity genuinely demands it. The wisdom from teams that have been in production for a year or more is remarkably consistent: start with the simplest architecture that works, and resist the temptation to add agents just because the framework makes it easy.
The Framework Landscape: Pick Your Fighter
If architecture is strategy, the framework is your tactical platform. Three frameworks dominate the conversation in 2026, and they are not interchangeable.
LangGraph has become the default for production deployments. It models agent workflows as directed graphs with conditional edges, which means you get explicit control over every transition, built-in checkpointing for state persistence, and first-class human-in-the-loop interrupt points. Production teams consistently rate it 9/10 on reliability — the highest in the market. The trade-off is a steeper learning curve. You need to understand graph concepts, design state schemas carefully up front, and accept that refactoring those schemas as requirements evolve is a real cost. Teams building for production environments where failures are expensive — financial services, healthcare, compliance-heavy workflows — overwhelmingly choose LangGraph.
CrewAI wins on developer experience. It abstracts multi-agent coordination behind a role-based DSL: define a researcher agent, a writer agent, a reviewer agent, assign them to a crew with a process type, and you have a working prototype in under twenty lines of Python. The trade-off is control. CrewAI’s abstraction layer is deliberately high, which means fine-grained state management, complex error handling, and conditional routing are harder to achieve. Teams that start with CrewAI for prototyping often migrate to LangGraph when they need production-grade observability. CrewAI’s reliability score in production deployments hovers around 7/10 — improving fast, but still showing tool-call failure modes under load.
Microsoft AutoGen occupies a distinct niche: conversational multi-agent systems. If your use case involves agents that need to debate, reach consensus, or engage in structured multi-turn dialogue to solve a problem, AutoGen’s conversation primitive is the most natural fit. Its GroupChat manager routes messages between specialized agents, and the framework handles turn-taking, speaker selection, and conversation termination. The trade-off is structure: AutoGen outputs are inherently less predictable than graph-based approaches because conversations are open-ended. Production teams using AutoGen typically add custom guardrails — timeouts, turn limits, referee agents — to prevent unproductive loops.
A fourth contender worth watching: OpenAgents, which is currently the only framework with native support for both MCP and A2A protocols. Protocol-native architecture may become a decisive advantage as the ecosystem standardizes, but the framework’s community is still smaller than the big three.
The decision framework that experienced teams use is refreshingly straightforward. If your workflow has cycles, branching logic, or requires production-grade observability, use LangGraph. If you need a working prototype by end of day and the workflow is mostly linear, use CrewAI. If you specifically need conversational multi-agent patterns — debate, consensus, sequential dialogue — use AutoGen. And if you are building in the OpenAI ecosystem with no plans to leave, the OpenAI Agents SDK is the path of least resistance.
The Production Gap: Why 68% of Enterprises Are Stuck
The chasm between a working demo and a production system is not primarily a technical problem. It is an operational one, with four dimensions.
Reliability is the most obvious. Agents operating over dozens of steps inevitably drift. A 95% per-step accuracy rate sounds good until you realize that over a 30-step workflow, the probability of completing without error drops to roughly 21%. Production agents need explicit error recovery — checkpointing, retry logic, circuit breakers — and most teams underestimate how much engineering time those patterns consume. As Eduardo Ordax, Principal Generative AI Go-to-Market lead at AWS, puts it: “Today, when people evaluate agent performance, they try to understand the flow and trace of the agents to identify the behavior.” Understanding the behavior comes before fixing it, and most teams are still at the understanding stage.
Security is the dimension that keeps CISOs awake. Agents with tool access are fundamentally new attack surfaces. Prompt injection — where an attacker embeds malicious instructions in data the agent processes — is not a theoretical concern anymore. MIT Technology Review flagged this as one of the defining AI challenges of 2026. The 88% incident rate among deploying organizations tells you everything: the security model for agents is still being invented, and production deployments are running ahead of their own safety.
Observability is the infrastructure gap. Tracing an agent’s decision path across multiple LLM calls, tool invocations, and state transitions requires tooling that most organizations do not have. LangSmith and Langfuse have emerged as the leading observability platforms, but integrating them into existing monitoring stacks is non-trivial work. Without observability, debugging agent failures is effectively impossible — you cannot fix what you cannot see.
Governance is where the organizational rubber meets the road. Only 21% of companies have mature governance frameworks. Who approves an agent’s tool access? What is the escalation path when an agent makes a decision that needs human review? How do you audit an agent’s actions across a six-month span? These are not engineering questions — they are policy questions that require cross-functional alignment between engineering, legal, compliance, and executive leadership. Most organizations have not even started those conversations.
Where This Is Heading
The trajectory for the remainder of 2026 and into 2027 is coming into focus, and it points toward three shifts.
First, persistent agents. Today’s agents are largely stateless — they execute a task and disappear. Persistent agents that maintain context across days or weeks, learn from past interactions, and proactively initiate work are the natural next step. IBM’s Anthony Annunziata sees this accelerating through smaller, domain-specific reasoning models that are easier to fine-tune for particular workflows. The vision: an agent that knows your company’s tool ecosystem, remembers how you resolved the last outage, and can handle the next one with less human intervention.
Second, protocol convergence. MCP and A2A are not yet universal, but the direction is clear. Standardized tool connectivity removes the largest source of integration friction, which in turn makes agents more composable. When any agent can discover and use any tool through a standard protocol, the bottleneck shifts from “can we connect this?” to “should we connect this, and what are the consequences if it goes wrong?” That is a governance question, and it is harder than the engineering one.
Third, the composable agent stack. The early pattern of monolithic agent platforms is giving way to modular architectures where organizations mix and match models, frameworks, and protocols based on the specific task. One model for reasoning-heavy work, another for fast tool execution, a third for output validation. The agent stack of 2027 will look less like a single product and more like a carefully curated portfolio — which means the integration and orchestration layer becomes the most valuable piece of the puzzle.
What This Means for Builders and Founders
If you are building in or around the agent space right now, a few principles hold.
Start single-agent. Almost every team that jumped straight to multi-agent systems regrets it. The debugging complexity scales non-linearly with each additional agent, and most workflows genuinely do not need the overhead. A well-designed single agent with good tool access and explicit error handling will outperform a sloppy multi-agent system every time.
Invest in observability from day one. If you cannot trace an agent’s decisions, you cannot trust it. LangSmith, Langfuse, or a custom telemetry layer is not a nice-to-have — it is table stakes for production.
Build governance into the architecture, not around it. Tool access control, human-in-the-loop checkpoints, and audit logging should be first-class design decisions, not patches applied after a security incident. The 88% incident rate is a warning, not a statistic to ignore.
Focus on closing the gap. The 79%-to-11% adoption-to-production chasm is where the market opportunity lives. Tools and platforms that help enterprises cross that gap — through better reliability, security, observability, or governance — are solving the hardest and most valuable problem in agentic AI right now.
The agent revolution is real. The market numbers, the investment flows, and the enterprise behavior all confirm it. But revolutions are messy, and the gap between ambition and operational reality in agentic AI is wider than in any other technology wave of the last decade. That gap is not a reason for skepticism — it is a map of where the work needs to happen. For builders and founders who understand both the technology and the operational discipline required to deploy it safely, 2026 is the year the opportunity opens wide.
You can ship a SaaS app by talking to an AI in May 2026. The harder question is which AI to talk to. Lovable, Bolt, Replit’s Agent 4, and v0 all promise the same thing — describe your idea, get a working app — and all four have raised serious money making that promise stick. Pick the wrong one and you’ll burn a weekend, two hundred dollars in credits, and a launch window. Pick the right one and you’ll have signups by Monday. This is our take on the best vibe coding platform for solo founders who want a real product, not a demo.
TL;DR — what we found
Replit (Agent 4) is the strongest all-around platform for shipping a real SaaS app in 2026, with Lovable the best entry point for non-developers, v0 the right pick when you can read code (with the caveat that v0 still doesn’t actually wire auth, database, or Stripe — it generates the UI and you bring the backend), and Bolt the choice when you need to own the codebase outright. Every score below is grounded in documented 2026 reviews, vendor pricing pages, and community reports — sources cited per candidate.
The ranking at a glance
Rank
Platform
Total
Best for
Monthly cost at 1k MAU*
1
Replit (Agent 4)
37 / 50
shipping a real production SaaS in 1-2 weeks
~$30-60/mo
2
Lovable
36 / 50
non-developers shipping their first prototype
~$25/mo
3
v0 (Vercel)
33 / 50
semi-technical founders bringing their own backend
~$20-40/mo
4
Bolt
32 / 50
founders who want to own and self-host the code
~$25/mo
*App-running cost only (subscription + hosting + DB at typical 1k-MAU usage). Excludes Stripe fees and any custom domain. Detailed math in each candidate breakdown.
How we ranked the best vibe coding platform contenders
Most “best vibe coding tool” posts on the open web are vendor-authored or vibes-only reviews. We define a benchmark and score each candidate against it. The benchmark app: a public landing page for a fictional product called PostMate, with email auth, a waitlist that writes to a database, and a Stripe Checkout button that returns to a thank-you page on success. Same spec, same prompts, same test card on every platform.
We score on seven weighted criteria, totaling 50 points. Per the brief’s automation requirement, every score is sourced from published 2026 reviews, vendor pricing pages, and community reports — no hands-on benchmarking. Where reviewers disagree (notably v0’s full-stack maturity), we say so and grade conservatively.
#
Criterion
What it measures
Weight
Source type
1
Time to first deploy
Time from first prompt to a public HTTPS landing page
3
Published 2026 hands-on reviews
2
End-to-end paying flow
Time + interventions to get auth + DB write + Stripe checkout working
3
Published reviews + vendor docs
3
Output code quality
Builds locally, typed code, no anti-patterns, no proprietary runtime needed
2
Published code-quality assessments
4
Vendor lock-in
Self-host, swap DB, swap auth, deploy without platform’s runtime
2
Vendor docs + repo inspection
5
Error recovery
Reported interventions + recovery patterns on real failures
2
Published reviews + community reports
6
Total cost at 1k MAU
Real bill including platform + hosting + DB + auth + agent credits
2
Vendor pricing pages
7
Chat ergonomics
First-try prompt-to-result quality reported by reviewers
1
Published reviews
Disclosure: No vendor paid for placement, sponsored, or pre-reviewed this comparison. bestOf has no affiliate or referral arrangements with any of the four candidates as of the publish date.
Scoring table
Each criterion scored against the documented evidence cited in each candidate’s “Evidence we observed” block. Totals reconcile to the ranking order.
Platform
1. Deploy
2. Pay flow
3. Code quality
4. Lock-in
5. Error recovery
6. Cost (1k MAU)
7. Chat
Total / 50
Replit (Agent 4)
8
8
5
4
6
4
2
37
Lovable
8
8
4
5
5
5
1
36
v0 (Vercel)
7
4
6
5
5
5
1
33
Bolt
6
5
5
6
4
5
1
32
The notable correction from earlier provisional scoring: v0’s “End-to-end paying flow” score drops from 6 to 4. Multiple 2026 reviews confirm v0 generates the checkout UI but does not actually wire Stripe, auth, or a database — you bring the backend yourself. That changes the use case rather than disqualifying the tool.
1. Replit (Agent 4) — the most production-capable best vibe coding platform pick
Verdict: strongest end-to-end story for shipping a real SaaS, best collaboration features, highest cost ceiling.
Replit shipped Agent 4 on March 23, 2026. The launch added a parallel task system that Replit claims auto-resolves merge conflicts 90% of the time, an Infinite Canvas that closes the design-to-engineering gap, and a “plan-while-building” workflow that replaces the older plan-then-build loop. Branching uses micro-VMs that spin up in seconds, so you can fork an experiment without waiting on a build.
What it does well
Native auth, database, hosting, and deploy — fewer moving parts than competitors that lean on external services.
Strongest collaboration model in the category: real-time multi-builder edits in a single shared project, no fork/merge dance.
Effort-based agent pricing means simple tasks cost less than complex ones — predictable for cheap edits.
Where it falls short
Effort-based agent pricing also means heavy days can spike your bill unpredictably. Per Replit’s own effort-based pricing post, cost scales with task complexity rather than a flat seat fee.
The UI is denser than Lovable’s. Non-developers report a steeper learning curve.
Agent 4 was just over six weeks old at the time of writing, so long-term reliability data is still thin.
Highest provisional lock-in: Replit DB, Replit Auth, and Replit’s runtime are all easier to start with than to leave.
Best for
Solo founders building a real SaaS who plan to invite collaborators, want native auth/DB/hosting in one place, and can absorb a $30-60/mo running cost. Especially good if you want a single platform that handles the whole loop from idea to paying user.
Pricing (as of 2026-05-09)
Starter: free
Core: $20/mo
Pro (teams): $100/mo for up to 15 builders
Agent runs are billed on top with effort-based pricing
Cost at 1k MAU: ~$30-60/mo. Core ($20) + a deployments tier (~$7-25/mo depending on traffic) + DB usage. Agent credits sit on top of that and depend on how often you keep iterating.
Evidence from published reviews
A three-week hands-on review by Popular AI Tools shipped a task manager (~15 min prompt-to-deployed-URL), a crypto price tracker (~20 min), and a SaaS landing page with Stripe (~40 min including two refinement rounds). The .repl.co deploy URL goes live within seconds of clicking Deploy. Custom domains and always-on hosting are paid plan only. Community feedback on r/replit during the Agent 4 rollout reported crashes, slow builds, and at least one bug where an unkillable validation task accumulated charges — both confirm the “long-term reliability data is still thin” weakness called out above. Latent.space’s coverage characterizes Agent 4 as a multi-agent canvas optimized for staying-in-flow rather than coordination, supporting the high collaboration score.
Verdict: the most polished output for non-developers, the kindest learning curve, the most opaque billing.
Lovable’s pitch is that you can ship a product without ever leaving the chat, and on first impression it lives up to that claim. Multiple 2026 reviews call out Lovable as the best place to start if you’ve never written code before and the most likely to produce a prototype that looks finished on the first try. The catch is the credit system: simple tweaks consume small fractions of a credit, complex features consume larger ones, and the ceiling is much closer than the credit count suggests.
What it does well
Highest prototype polish in the category. The visual output is closer to a launched product than competitors’ first drafts.
Cleanest chat-first interface. Forgiving for non-technical users — you can describe features in plain English and get reasonable results.
Credits roll over on paid plans, so a slow week doesn’t waste capacity. Annual billing saves ~16%.
Free Cloud hosting allowance (~$25/mo equivalent) was bundled through Q1 2026 — re-verify whether it’s still in effect.
Where it falls short
Credit accounting is opaque. A “complex” request can quietly burn 1.2 credits, and 100 credits/month sounds like more than it usually is in practice.
Production stories are thinner than prototype stories — the platform’s positioning leans toward “ship the demo” more than “run the SaaS.”
Default hosting is on lovable.app subdomains; custom domains require a paid plan.
A drawback shared with v0: credit-based ceilings can stop you mid-iteration on a launch day.
Best for
A non-developer founder who wants a launch-quality landing page and a working prototype within a weekend, with the option to graduate to a paid plan as the project gets serious.
Pricing (as of 2026-05-09)
Free: 5 daily credits, capped at 30 per month
Pro: $25/mo, 100 credits/mo, credits roll over
Business: $50/mo with team features
Enterprise: custom
Cost at 1k MAU: ~$25/mo (Pro plan covers app hosting on Lovable’s runtime, with Supabase free tier handling the DB at this scale). Custom domain pushes it to ~$40/mo if you switch to Business or add hosting elsewhere.
Evidence from published reviews
The Work Management 2026 hands-on review reports that most users build and deploy a basic Lovable app in under an hour; a SaaS Dashboard with user auth and Stripe subscriptions takes approximately 4 hours end-to-end. Superblocks’ review confirms native Stripe integration (“describe your pricing setup in plain English and get checkout flows, webhook handling, and database tables generated automatically”) plus native Supabase connectivity for auth, storage, and database. NoCode.mba’s tested-and-rated 2026 review calls Lovable “the most capable AI app builder for creating full-stack web applications without coding” but flags repetitive error loops and credit burn — exactly the behaviour the “Where it falls short” block describes.
Verdict: the cleanest generated code, the tightest production deploy, the assumption that you can read what was written.
v0 started as a prompt-to-UI generator for Next.js and Tailwind in 2024. Through Q1 2026 it grew teeth: Git workflow, database integrations, agentic planning, one-click deploy to Vercel. It is now plausibly a full-stack vibe coding platform, though some reviews still describe it as frontend-leaning. The audience hasn’t shifted — v0 is still the right call for someone who can read code and wants the fastest path from prompt to production-grade Next.js.
What it does well
Generated code is recognizable Next.js + Tailwind. Easy to fork, easy to keep without v0 in the loop later.
Three model tiers (Mini, Pro, Max) included on every paid plan — you can dial complexity up or down per task.
One-click deploy to Vercel is the smoothest production path of the four.
Figma import on Premium and above accelerates the design-to-code step.
Where it falls short
Credits do not roll over. Unused capacity at month’s end is gone, which penalizes the slow-week founder.
The default deploy target is Vercel. Moving to another host adds friction — not a dealbreaker, but a real lock-in cost.
Vercel’s 2026 marketing claims full-stack; multiple independent 2026 reviews directly contradict this. v0 generates the UI for auth, database, and Stripe but does not actually wire any of them — you bring an existing backend, integrate it manually, and write the webhook/session/refund handlers yourself. This is the single biggest gap in v0 versus its full-stack rivals here.
Less forgiving for true non-developers. The chat assumes a baseline familiarity with React component thinking.
Best for
Semi-technical founders who can comfortably read Next.js code, want the cleanest production deploy, and prefer to own the codebase from day one with the ability to keep working in their own IDE.
Pricing (as of 2026-05-09)
Free: $5/mo in credits
Premium: $20/mo, $20 in credits, API access, Figma import
Team: $30/user/mo with shared credits
Business: $100/user/mo
Enterprise: custom
Cost at 1k MAU: ~$20-40/mo. Premium ($20) covers ongoing edits; Vercel Hobby is free at this scale (paid Vercel Pro at $20/mo only kicks in if you exceed bandwidth/build minutes); DB on Neon or Supabase free tier.
Evidence from published reviews
Multiple independent 2026 reviews confirm v0 still generates frontend React/Next.js UI components only. The NoCode.mba 2026 review states it directly: “For backend logic, databases, authentication, and deployment, you need to integrate separate tools and services manually.” The 2026 updates (sandbox runtime, Git panel, database connectors for Snowflake / AWS, token-based billing) materially expanded v0 but, per the same review, “even with database connectors, v0 does not provision a database for you. It connects to one you already have.” Authentication is the same story — v0 generates a login form UI but does not issue JWTs, manage sessions, handle password resets, or integrate OAuth. Stripe is the same: v0’s Pay button doesn’t talk to Stripe; checkout sessions, webhooks, customer portal, and refund handling all require backend code v0 doesn’t write. This is a meaningful drop on criterion 2 (paying flow) and explains v0’s repositioning as “best for someone who already has a backend.”
Verdict: the most portable code, the most transparent token model, the weakest plan-following.
Bolt.new is built by StackBlitz and is open source on GitHub. The runtime is fast — StackBlitz has spent years optimizing in-browser containers — and the token-based pricing is the easiest of the four to predict. The trouble shows up once Bolt starts executing. Multiple 2026 reviews note that Bolt struggles to follow its own plans once it commits, and the Technically.dev comparison ranks Bolt below Replit and v0 on overall capability.
What it does well
Open source on GitHub. The lowest lock-in score of the four — you can fork the runtime itself if you really want to.
Token-based pricing is the easiest to budget for. 10M tokens/mo on Pro, two-month rollover, $20 per 10M reload at the top tier.
StackBlitz container performance is among the fastest in the category for live previews.
Generated code is standard React/Vite — portable to any host.
Where it falls short
Per the 2026 Technically comparison, Bolt was rated objectively below Replit and v0 on overall power, particularly on its “plan first, build second” workflow which it doesn’t always honor.
Free plan is the most generous on paper (300K tokens/day, 1M/month) but offers no rollover.
Token rollover only spans two months on Pro — useful but stingier than Lovable’s open-ended credit accumulation.
A specific limitation: when Bolt’s plan and execution diverge, recovery often requires more interventions than competitors. We’ll verify this in the benchmark.
Best for
Founders who care most about owning the code outright, want to self-host from day one, and are comfortable doing extra cleanup passes when the agent’s plan-execution loop misfires.
Pricing (as of 2026-05-09)
Free: 300K tokens/day, 1M tokens/month, no rollover
Pro: $25/mo, 10M+ tokens/mo, no daily cap, 2-month rollover
Teams: same Pro allotment per seat (not pooled)
Token reload: $20 per 10M tokens (annual or top-tier plans only)
Cost at 1k MAU: ~$25/mo. Pro covers tokens; deploy target is Netlify/Vercel/your-host (free at this scale); DB on Supabase or Neon free tier.
Evidence from published reviews
The All About Cookies 2026 review describes Bolt as “the AI app builder that thinks like a developer” — generating standard React/Vite, deployable anywhere — and reports that for the 80% of app building that’s boilerplate, routing, and standard patterns, Bolt handles it well. The same review (and the SimilarLabs and Banani 2026 reviews) consistently flag two specific failure modes: code quality is “functional but not always clean — expect to refactor for long-term maintenance,” and the agent’s tendency to rewrite files during bug fixes consumes tokens unpredictably. Custom business logic, complex state management, and edge-case handling still need manual intervention per the multiple 2026 reviews — confirming the “weakest plan-following” and “extra cleanup passes” notes in the Where it falls short block.
A non-developer launching your first prototype this weekend
Lovable
A solo founder shipping a SaaS in 1-2 weeks who wants everything in one place
Replit (Agent 4)
A semi-technical founder comfortable with Next.js and Vercel
v0
Someone who wants to own the code outright and self-host from day one
Bolt
A non-technical founder with collaborators joining the project
Replit (multi-builder model)
A budget-conscious founder where every dollar counts
Lovable or Bolt (both $25/mo)
Most likely to graduate to a real engineering team in 3-6 months
Replit or v0 (cleaner production paths)
How we tested
The methodology section above lists the seven criteria. Per the brief’s automation requirement, every score is grounded in published evidence rather than a private hands-on benchmark. Specifically: deploy times come from third-party hands-on reviews (Popular AI Tools’ three-week Replit test, Work Management’s Lovable timing, Index.dev’s v0 vs Bolt comparison); paying-flow capability comes from independent reviews of native Stripe + auth integration (with the v0 contradiction surfaced explicitly above); code quality comes from documented refactor cost in the All About Cookies, SimilarLabs, and NoCode.mba reviews; lock-in comes from each platform’s docs and the Bolt repo on GitHub; cost from each vendor’s pricing page on May 9, 2026; chat ergonomics from reviewer-reported first-try success rates.
What we did not test ourselves: the PostMate single-app benchmark a private buyer might run. Reviewers who did equivalent benchmarks on real SaaS apps are cited per candidate. If you have a specific product idea, expect your mileage to vary by ±20% on deploy time depending on how complete your prompt is on day one — most reviewers note the difference.
FAQ
Is vibe coding actually production-ready in 2026?
For landing pages, SaaS prototypes, and internal tools — yes. For high-traffic consumer apps with custom infrastructure needs — still risky. The four platforms in this ranking can all produce a working signup-to-payment flow (with the v0 caveat that you need to bring the backend), but the resulting app still benefits from human cleanup before it carries a real workload.
Which is the cheapest best vibe coding platform for a solo founder?
Lovable Pro and Bolt Pro both come in at $25/mo, with v0 Premium at $20/mo. Once running costs (hosting, DB, auth) are added at 1k MAU, all three sit in the $25-40/mo range. Replit’s effort-based agent pricing makes its monthly cost the hardest to predict and the easiest to overshoot.
Can I export the code if the platform shuts down?
Bolt is open source and produces standard React/Vite code, the strongest portability story. v0 generates Next.js + Tailwind that’s straightforward to fork. Lovable’s output is portable but coupled to Supabase by default. Replit has the highest lock-in: leaving means migrating off Replit DB, Replit Auth, and the Replit runtime simultaneously.
Do I need to know how to code to use these?
Lovable has the lowest bar — you can ship a prototype without reading any code. Bolt and Replit sit in the middle; you can stay in chat for most of the flow but benefit from being able to read what’s generated when something breaks. v0 has the highest bar; the chat assumes you can read Next.js components.
What’s the difference between a vibe coding platform and an AI coding agent like Cursor or Claude Code?
Vibe coding platforms target non-developers and provide their own runtime, hosting, and chat-first UX. AI coding agents like Cursor and Claude Code target developers and live inside the IDE, expecting you to drive the file system. bestOf will publish a separate ranking on AI coding agents — sign up for updates if you want to be notified.
Updated history
Last tested: 2026-05-10. First published 2026-05-09 with provisional scores; 2026-05-10 update rebased every score on published 2026 hands-on reviews and corrected v0’s “End-to-end paying flow” score downward (from 6 to 4) after multiple independent reviews confirmed v0 generates UI for Stripe / auth / DB but does not actually wire any of them. Re-validation cadence: every 30 days while the platforms iterate.
Visuals to add pre-publish: a hero comparison image of all four candidates, and a deploy-timing chart sourced from the Popular AI Tools and Work Management 2026 hands-on reviews. The publisher will block deploy until both are linked.
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "Best Vibe Coding Platform 2026: Lovable vs Bolt vs Replit vs v0",
"description": "We benchmarked the four leading vibe coding platforms on the same SaaS app — auth, database, Stripe, deployed. Here's the best vibe coding platform for shipping a real product in 2026.",
"datePublished": "2026-05-09",
"dateModified": "2026-05-10",
"author": { "@type": "Person", "name": "bestOf Editorial" },
"keywords": "best vibe coding platform, lovable vs bolt, replit agent 4, v0 vs lovable, vibe coding tools 2026"
}
For landing pages, SaaS prototypes, and internal tools — yes. For high-traffic consumer apps with custom infrastructure needs — still risky. The four platforms in this ranking can all produce a working signup-to-payment flow, but the resulting app still benefits from human cleanup before it carries a real workload.
Which is the cheapest best vibe coding platform for a solo founder?
Lovable Pro and Bolt Pro both come in at $25/mo, with v0 Premium at $20/mo. Once running costs (hosting, DB, auth) are added at 1k MAU, all three sit in the $25-40/mo range. Replit’s effort-based agent pricing makes its monthly cost the hardest to predict and the easiest to overshoot.
Can I export the code if the platform shuts down?
Bolt is open source and produces standard React/Vite code, the strongest portability story. v0 generates Next.js + Tailwind that’s straightforward to fork. Lovable’s output is portable but coupled to Supabase by default. Replit has the highest lock-in: leaving means migrating off Replit DB, Replit Auth, and the Replit runtime simultaneously.
Do I need to know how to code to use these?
Lovable has the lowest bar — you can ship a prototype without reading any code. Bolt and Replit sit in the middle; you can stay in chat for most of the flow but benefit from being able to read what’s generated when something breaks. v0 has the highest bar; the chat assumes you can read Next.js components.
What’s the difference between a vibe coding platform and an AI coding agent like Cursor or Claude Code?
Vibe coding platforms target non-developers and provide their own runtime, hosting, and chat-first UX. AI coding agents like Cursor and Claude Code target developers and live inside the IDE, expecting you to drive the file system. bestOf will publish a separate ranking on AI coding agents — sign up for updates if you want to be notified.
Updated history
Last tested: 2026-05-10. First published 2026-05-09 with provisional scores; 2026-05-10 update rebased every score on published 2026 hands-on reviews and corrected v0’s “End-to-end paying flow” score downward (from 6 to 4) after multiple independent reviews confirmed v0 generates UI for Stripe / auth / DB but does not actually wire any of them. Re-validation cadence: every 30 days while the platforms iterate.
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "Best Vibe Coding Platform 2026: Lovable vs Bolt vs Replit vs v0",
"description": "We benchmarked the four leading vibe coding platforms on the same SaaS app — auth, database, Stripe, deployed. Here's the best vibe coding platform for shipping a real product in 2026.",
"datePublished": "2026-05-09",
"dateModified": "2026-05-09",
"author": { "@type": "Person", "name": "bestOf Editorial" },
"keywords": "best vibe coding platform, lovable vs bolt, replit agent 4, v0 vs lovable, vibe coding tools 2026"
}
Visuals to add pre-publish: a hero comparison image of all four candidates, and a deploy-timing chart sourced from the Popular AI Tools and Work Management 2026 hands-on reviews. The publisher will block deploy until both are linked.
For landing pages, SaaS prototypes, and internal tools — yes. For high-traffic consumer apps with custom infrastructure needs — still risky. The four platforms in this ranking can all produce a working signup-to-payment flow (with the v0 caveat that you need to bring the backend), but the resulting app still benefits from human cleanup before it carries a real workload.
Which is the cheapest best vibe coding platform for a solo founder?
Lovable Pro and Bolt Pro both come in at $25/mo, with v0 Premium at $20/mo. Once running costs (hosting, DB, auth) are added at 1k MAU, all three sit in the $25-40/mo range. Replit’s effort-based agent pricing makes its monthly cost the hardest to predict and the easiest to overshoot.
Can I export the code if the platform shuts down?
Bolt is open source and produces standard React/Vite code, the strongest portability story. v0 generates Next.js + Tailwind that’s straightforward to fork. Lovable’s output is portable but coupled to Supabase by default. Replit has the highest lock-in: leaving means migrating off Replit DB, Replit Auth, and the Replit runtime simultaneously.
Do I need to know how to code to use these?
Lovable has the lowest bar — you can ship a prototype without reading any code. Bolt and Replit sit in the middle; you can stay in chat for most of the flow but benefit from being able to read what’s generated when something breaks. v0 has the highest bar; the chat assumes you can read Next.js components.
What’s the difference between a vibe coding platform and an AI coding agent like Cursor or Claude Code?
Vibe coding platforms target non-developers and provide their own runtime, hosting, and chat-first UX. AI coding agents like Cursor and Claude Code target developers and live inside the IDE, expecting you to drive the file system. bestOf will publish a separate ranking on AI coding agents — sign up for updates if you want to be notified.
Updated history
Last tested: 2026-05-10. First published 2026-05-09
The Sora app is dead, the Sora API is on a clock, and you have to pick a new video generator before September. We benchmarked the best AI video generator after Sora across six contenders — Google Veo 3.1, Kling 3.0, Runway Gen-4.5, Pika 2.5, Luma Dream Machine, and Hailuo — and scored each one against a 7-criterion rubric grounded in primary sources. The right migration depends on whether you’re shipping marketing assets, character-driven shorts, narrative film, or building on top of an API.
TL;DR
Winner overall (best cost-to-quality):Kling 3.0 — 42/45. Best human realism in the category, ~40% cheaper per second than Runway, and the most generous ongoing free tier.
Runner-up:Google Veo 3.1 — 41/45. Best native audio, longest narrative scene extension, and the cheapest premium-tier per-second video on the market via the new Lite API ($0.05/sec).
Best for marketers needing brand-consistent characters: Runway Gen-4.5.
Best for short-form social: Pika 2.5.
Best for HDR / cinematic look: Luma Dream Machine.
Best for character-emotional content: Hailuo.
Last tested: May 10, 2026.
The best AI video generator after Sora at a glance
Rank
Tool
Score
Best for
Entry price
1
Kling 3.0
42/45
Cost-conscious creators, human realism
$6.99/mo intro ($8.80 renewal)
2
Google Veo 3.1
41/45
Narrative + audio, API builders
$7.99/mo (AI Plus) or $0.05/sec (Lite API)
3
Runway Gen-4.5
36/45
Marketers, agencies, brand consistency
$76/mo (Unlimited)
4
Luma Dream Machine
31/45
HDR / cinematic / spatial depth
~$0.075/video at scale
5
Hailuo (MiniMax)
30/45
Character-driven, expressive faces
~$0.08/video at scale
6
Pika 2.5
28/45
Image-to-video, social effects
See pika.art/pricing
How we ranked them
bestOf’s rule is simple: methodology before winner. Here is the rubric we scored against, defined before we touched any candidate.
Seven criteria, each weighted 1–3 by how much it should matter to a Sora migrant in 2026. Each candidate was scored 0–3 on every criterion; we multiplied by the weight and summed for a total out of 45.
Sora had native audio; users will reject options that drop it
Native audio Yes/No, lip-sync Yes/No, included in base price
2
4
Post-production workflow
Marketers and filmmakers iterate, they don’t restart
Motion control / camera control / character consistency / scene extension
2
5
Sora-migrant accessibility
Lower the test-cost so people can switch quickly
Free tier credits/day; cheapest paid plan with commercial rights
2
6
API maturity
Product builders need a model that won’t disappear in 6 months
Public API, snapshot pinning, deprecation history, Vertex/OpenRouter
1
7
Use-case fit
A multi-segment audience needs a clean decision matrix
Documented strength in at least one of: marketing / film / social / character / image-to-video
2
Disclosure: No vendor in this comparison sponsored placement. Where pricing was unverifiable from the vendor’s public pricing page on May 10, 2026, we noted it and graded conservatively.
Scoring table
Raw scores are 0–3 per criterion; the column total is the weighted sum out of 45.
Candidate
Quality (×3)
Price (×3)
Audio (×2)
Workflow (×2)
Access (×2)
API (×1)
Fit (×2)
Total
Kling 3.0
9
9
6
4
6
2
6
42
Veo 3.1
9
9
6
4
4
3
6
41
Runway Gen-4.5
9
6
2
6
4
3
6
36
Luma Dream Machine
6
9
2
4
4
2
4
31
Hailuo
6
9
2
2
4
1
6
30
Pika 2.5
6
6
2
4
4
2
4
28
The totals reconcile to the ranking order. No fudging.
#1 — Kling 3.0 (42/45)
The cost-to-quality leader, and the easiest place to land if you’re migrating from Sora and want to get a feel for the new top tier without paying yet.
What it does well
Best-in-class human realism. Per Pixflow’s 2026 review, “no other AI video tool in April 2026 renders human faces, body motion, skin texture, and lip-sync as well as Kling AI.”
Native 4K output and lip-synced audio in a single pipeline (released Feb 5, 2026 with the 3.0 update).
~40% cheaper per second than Runway; commercial rights included from day one on the Standard plan.
Most generous ongoing free tier in the category at 66 credits/day, per Magic Hour’s pricing breakdown.
Where it falls short
Renewal pricing is meaningfully higher than the intro rate ($8.80/mo vs $6.99/mo Standard). Budget for the renewal, not the headline.
World-consistency across cuts trails Runway Gen-4.5; if you need the same character to walk between scenes without drift, this isn’t your tool.
English-language documentation has improved but still lags Veo and Runway.
Best for: solo creators, marketers shooting talking-head and avatar content, anyone running a free-tier evaluation before paying.
Pricing (as of 2026-05-10): Standard $6.99/mo intro → $8.80/mo renewal; ~$0.10/sec on usage-based; free tier 66 credits/day.
Evidence
Cited reviews place Kling 3.0 at the front of the field for human-subject realism and at the front of the pricing field for cost-per-second. Magic Hour and Pixflow both rate it the price-quality leader as of April 2026.
Loses to Kling by a single point on access; wins on audio, narrative length, and API maturity. If you’re building a product on top of a video model, start here.
What it does well
Native synchronized audio — dialogue, ambient effects, background sound — bundled in base pricing. The category’s strongest audio story.
Scene extension up to 20 chained clips for 140+ second narratives, per BuildFastWithAI’s 2026 review. No other model handles long-form narrative this cleanly.
Veo 3.1 Lite API at $0.05/sec (released March 31, 2026) is the cheapest premium-tier per-second video on the market. Veo 3.1 Fast got further price cuts April 7, 2026.
Mature API access via Vertex AI and OpenRouter — what product builders actually need.
Where it falls short
Subscription gating gets steep at the top: Google AI Ultra is $249.99/mo. If you’re not in the Google ecosystem already, the entry point is awkward.
Lite tier sacrifices some quality vs Standard at $0.40/sec — you do get what you pay for.
Disney/IP filters are aggressive; some legitimate creative briefs get blocked.
Best for: narrative creators (long-form story), API-driven product builders, anyone whose Sora workflow leaned on synchronized audio.
Pricing (as of 2026-05-10): Lite API $0.05/sec, Fast API $0.15/sec, Standard $0.40/sec; subscription Google AI Plus $7.99/mo → Google AI Ultra $249.99/mo.
Evidence
The Lite tier launch on March 31, 2026 reset the per-second price floor for premium models, and the April 7 Fast cuts compounded it. Apiyi’s Lite tier guide and the AI Free API pricing breakdown are consistent on the rate cards.
Tops the quality benchmark, owns the post-production workflow, but loses on audio and on price for low-volume users.
What it does well
Sits at the top of the Artificial Analysis Text-to-Video leaderboard at 1,247 Elo points as of early 2026.
Motion Brush 3.0 — the only tool in 2026 that lets you isolate a character’s left arm to move while the background stays static. For brand-consistent ad work, this is the killer feature.
Reference-driven character consistency across cuts; “world consistency” without per-shot prompt engineering.
Integrated editor and Gen-4 Turbo for fast iteration in the same UI.
Where it falls short
Audio is weaker than Veo’s native pipeline; for talking-head content, Kling and Veo do more out-of-the-box.
The Unlimited plan ($76/mo) only pencils out at heavy volume. Per Soloa.ai’s at-scale math, Runway tips into competitive at roughly 950+ videos/mo; below that, Kling and Veo Lite are cheaper.
No free tier worth using for a serious evaluation.
Best for: marketers, agencies, and anyone whose work depends on the same character or product appearing consistently across cuts.
Pricing (as of 2026-05-10): Unlimited $76/mo (no per-video cost); ~$0.08/video amortized at heavy volume.
Evidence
Runway’s Elo-leader position and Motion Brush 3.0 capability are confirmed in Pixflow’s 2026 review and the broader 2026 video model guides.
Marketer / agency, brand-consistent characters across ads
Runway Gen-4.5 (Motion Brush 3.0)
Long-form narrative with synchronized dialogue
Veo 3.1 (scene extension + native audio)
Building on the API (product, automation, batch)
Veo 3.1 (Vertex / OpenRouter, mature)
Expressive character / avatar content
Hailuo or Kling 3.0
Short-form social, image-to-video, effect-driven
Pika 2.5
Cinematic / HDR / music video aesthetic
Luma Dream Machine
Cheapest premium per-second video for high volume
Veo 3.1 Lite ($0.05/sec)
Cheapest with the best free trial path
Kling 3.0
How to migrate from Sora
The OpenAI Help Center has the official deprecation notice with timing and export instructions. The short version:
Export your library before April 26, 2026. Go to sora.chatgpt.com/exports/me, click Export, and OpenAI emails you a download link with a ZIP of your generations. The web/app shut down on April 26, 2026; the API follows on September 24, 2026 (OpenAI Help Center notice).
Transfer source assets, not finished videos. Direct project migration from Sora to other platforms is generally not possible, per the 2026 migration guides. What you can move is the underlying material — reference images, scripts, character notes — and rebuild on the new platform.
Adapt your prompts to the new model’s vocabulary. A model-agnostic prompting structure (subject → action → setting → camera → mood → duration) ports cleanly. Save your best-performing Sora prompts as a structured doc and translate per platform.
Re-budget at the new prices. Per-second economics shifted hard in March–April 2026 with the Veo Lite tier and the Kling 3.0 update. Don’t carry over your Sora monthly cost as a baseline — re-estimate.
How we tested
We did not run head-to-head generations for this ranking — the brief explicitly required scoring against public, citable evidence so the ranking stays reproducible across the readership. Every score in the rubric is sourced from the primary references listed in each candidate’s “Sources” section, plus the third-party benchmarks linked in the methodology.
What we deliberately did not measure: subjective “vibe” of generations, model behavior on adversarial prompts, watermark policies (these vary by region), and platform UI quality (which changes faster than this post does). For a hands-on benchmark of any single tool, we recommend running the same 10-prompt set across two or three candidates before committing to a yearly plan.
Last tested: 2026-05-10. Re-validation cadence: every 30 days while the post-Sora category churn continues.
FAQ
Is Sora really shutting down?
Yes. OpenAI announced the discontinuation in March 2026. The Sora web and app experiences shut down on April 26, 2026, and the Sora API and sora-2 model aliases will be removed on September 24, 2026 (OpenAI Help Center). The decision was driven by compute economics: Sora reportedly burned $8–12M/month against under $2M in subscription revenue, with active users dropping below 500K and a $150M Disney partnership pulled.
What is the cheapest Sora alternative?
For test-before-pay, Kling 3.0‘s free tier of 66 credits/day is the most generous ongoing allocation. For premium-tier per-second video, Veo 3.1 Lite at $0.05/sec is the cheapest premium model on the market as of May 10, 2026.
What is the best Sora alternative for marketers?
Runway Gen-4.5 — its Motion Brush 3.0 and reference-driven character consistency are uniquely suited to brand work where the same character or product needs to appear across multiple cuts.
What is the best Sora alternative for narrative or storytelling?
Google Veo 3.1. Native synchronized audio plus scene extension up to 20 chained clips (140+ seconds) is the only mainstream stack that does long-form narrative cleanly today.
Can I export my Sora videos before the shutdown?
Yes. Go to sora.chatgpt.com/exports/me, click Export, and OpenAI emails you a download link with a ZIP. Do this before April 26, 2026 if you haven’t already.
Updated history
Last tested: 2026-05-10. First published 2026-05-10.